Elon Musk recently pivoted Tesla from manufacturing cars to autonomous vehicles & robots. His vision of automated manual work a thing of the not-too-distant future propping up Tesla's valuation ($1.2 trillion at current time of writing) as car sales decline.
Robots are coming
Current demos of Musk's Optimus robots show them doing basic tasks in controlled environments such as folding shirts and sorting batteries into boxes.

Anecdotally, on Instagram the other day I watched a video of a robot loading wine glasses delicately into a dishwasher - suggesting the dexterity of robots has increased to a significant level.
That said, I've also watched a variety of robot fail videos too, including the now famous Russian robo-fail video.

My broad takeaway is that progress in robotics is impressive, but there's a long way to go.
Importance of World Models
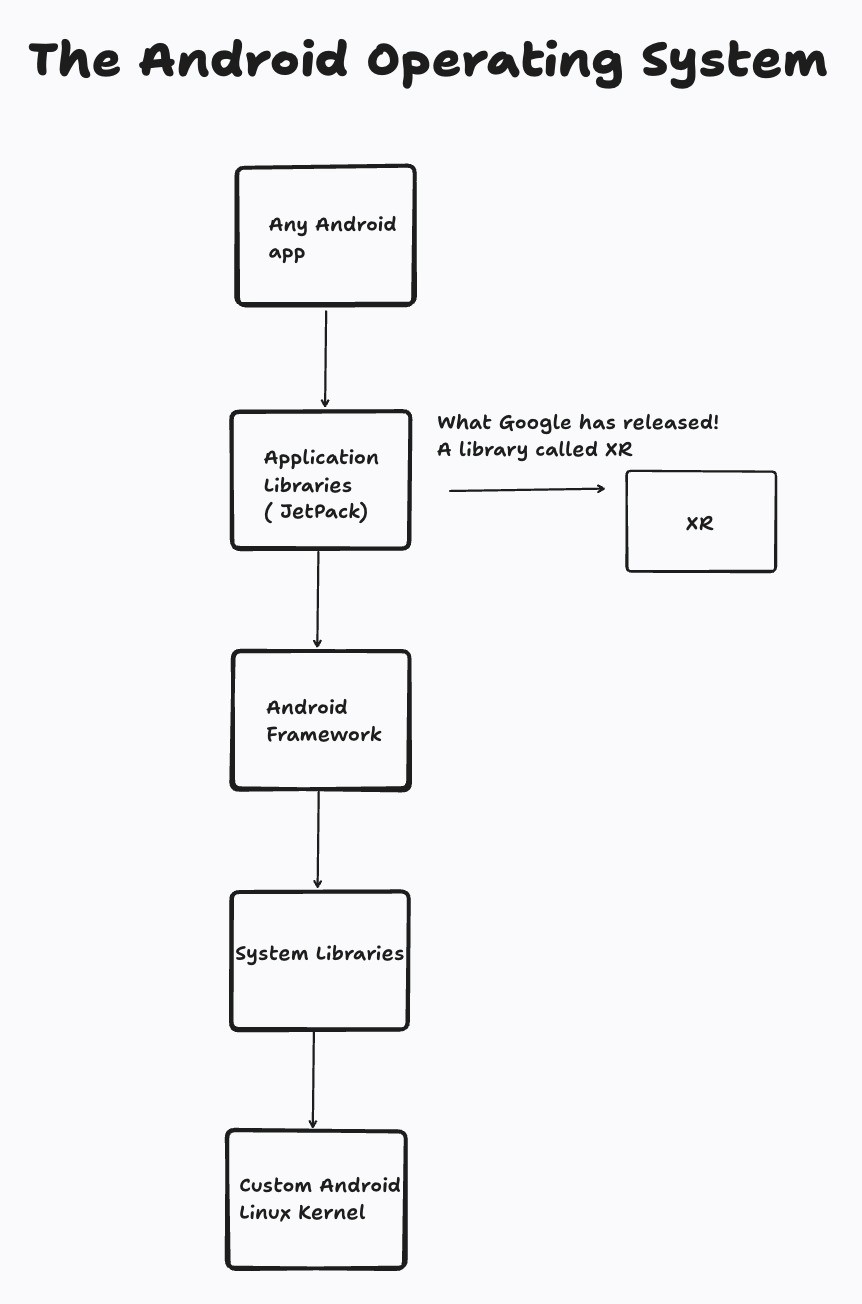
Accelerated progress in autonomous robots is linked to advancements of AI, and in particular World Models. World Models are distinct from Large Language Models (LLMs) which most of us are familiar with, and power apps like ChatGPT etc.
In simple terms, World Models model the 'physical world intelligence' i.e. the bit of human intelligence that allows us to interact with the real world and do stuff. If you think of a human's intelligence, we have multiple levels of sophistication that enable us to do what we can do; we're not just a brain that can think and talk, but a physical being that can think, talk, move and interact.
The Large Language Model does the 'thinking' bit, and the World Model does the 'doing' bit - by helping the robot 'imagine before acting'.
But the doing bit is magnitudes more complex to model than the thinking bit.
Autonomous vehicles and low dimension problems
Consider self-driving cars. It took c.15 years of R&D to produce an autonomous vehicle (worked started in c.2005, and the first Waymo-powered cars took to the streets in San Francisco in c.2020), but if you consider the complexity of the world problem that self-driving cars master it's relatively trivial.
Breaking down the main goal of autonomous vehicles to their core, their main goal is to 'not bump into anything else' - i.e. stop / swerve as quickly as possible when it's understood that there's an object in the way.

As impressive and futuristic as self-driving cars are, they're the low hanging fruit of World AI as they're only solving a very 'low dimension' problem. Low dimension in that the autonomous vehicle is operating in a fairly controlled environment with a single 'not goal' (i.e. don't crash!).
Real world complexity
When you compare an autonomous vehicle to say a Robo Tradesperson, the levels of complexity increase dramatically - in particular in relation to the infinite variables that real world environments pose to a Robo Tradesperson, compared to controlled environments of the autonomous vehicle where the variables are more easily predicted.
Just consider a simple scenario where an tradesperson visits your house to do a maintenance check on your intruder alarm. The engineer needs to:
a) locate the main system panel in the basement (down steep stairs)
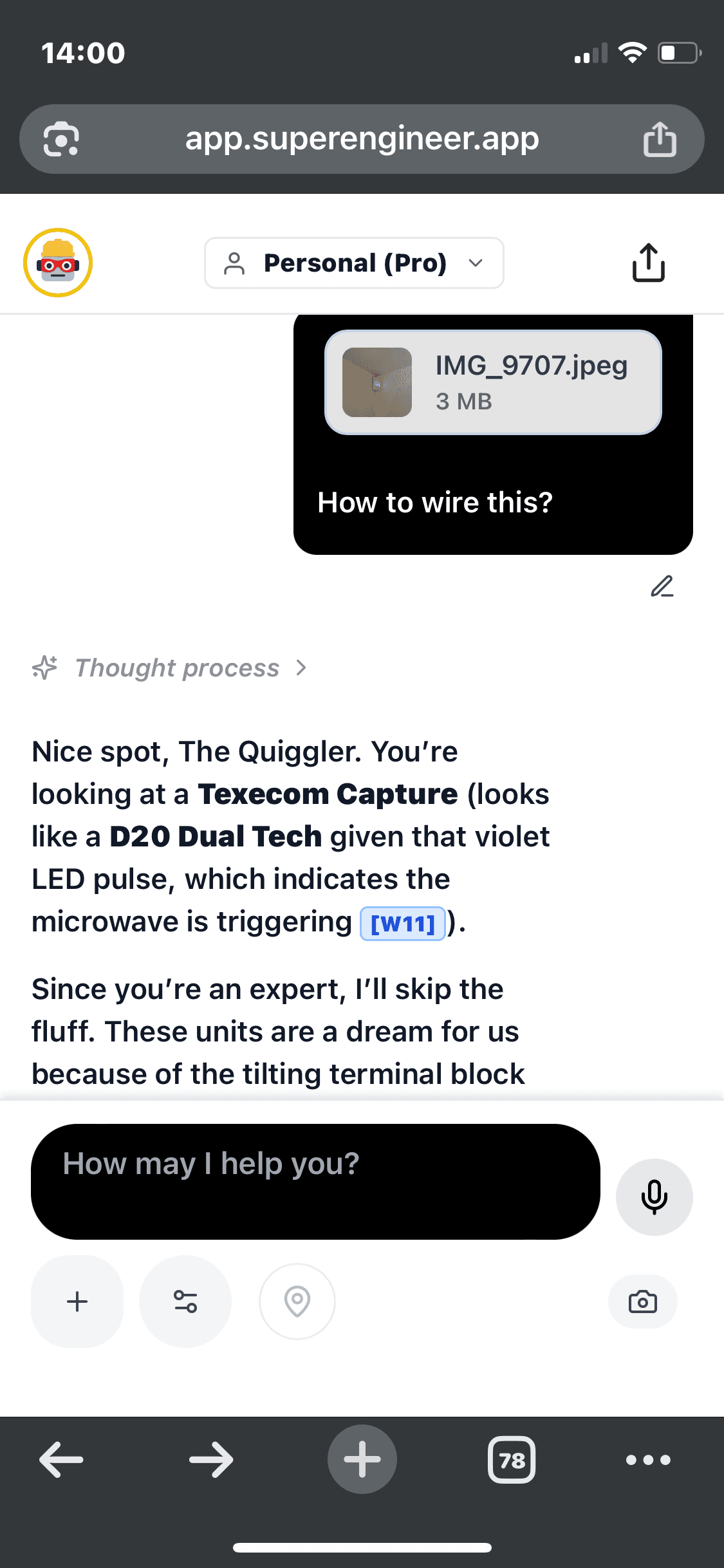
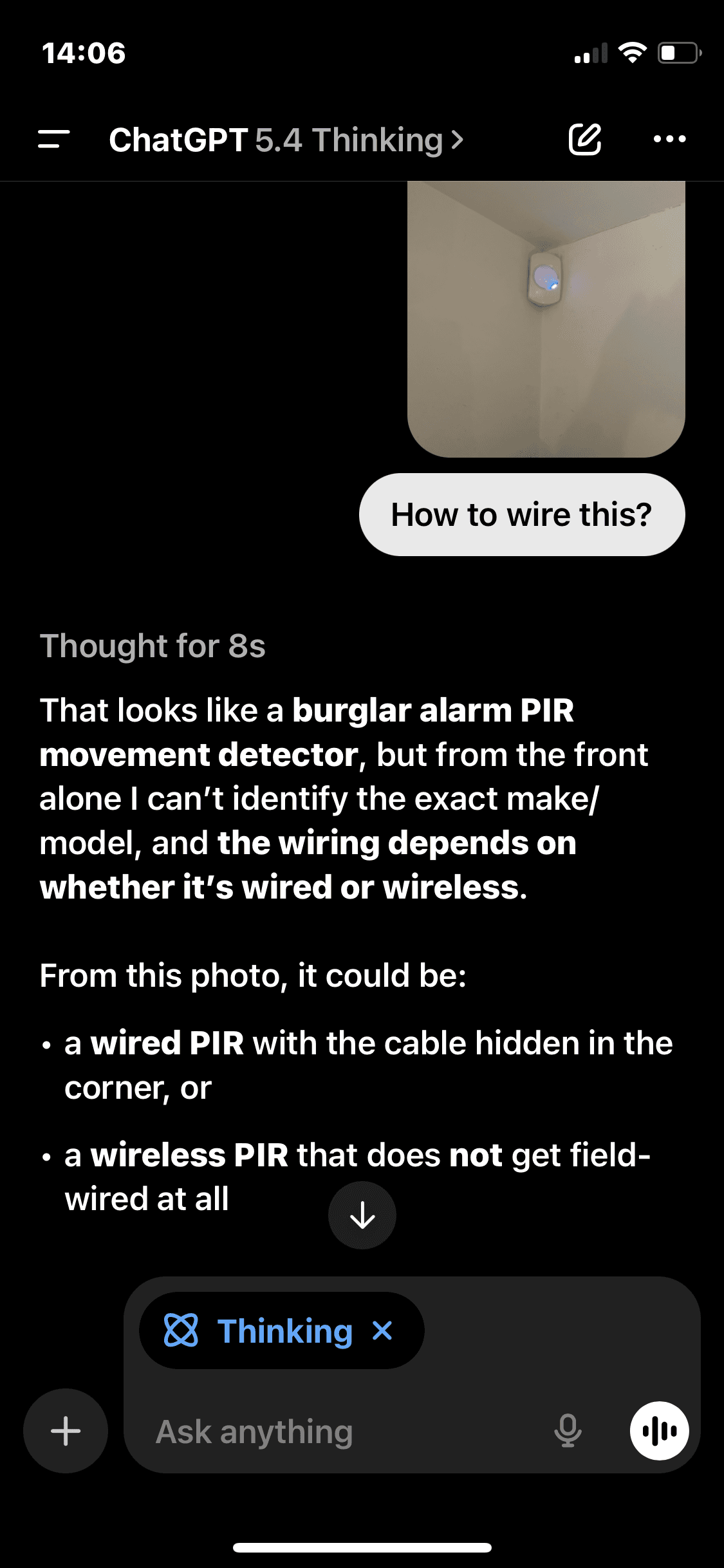
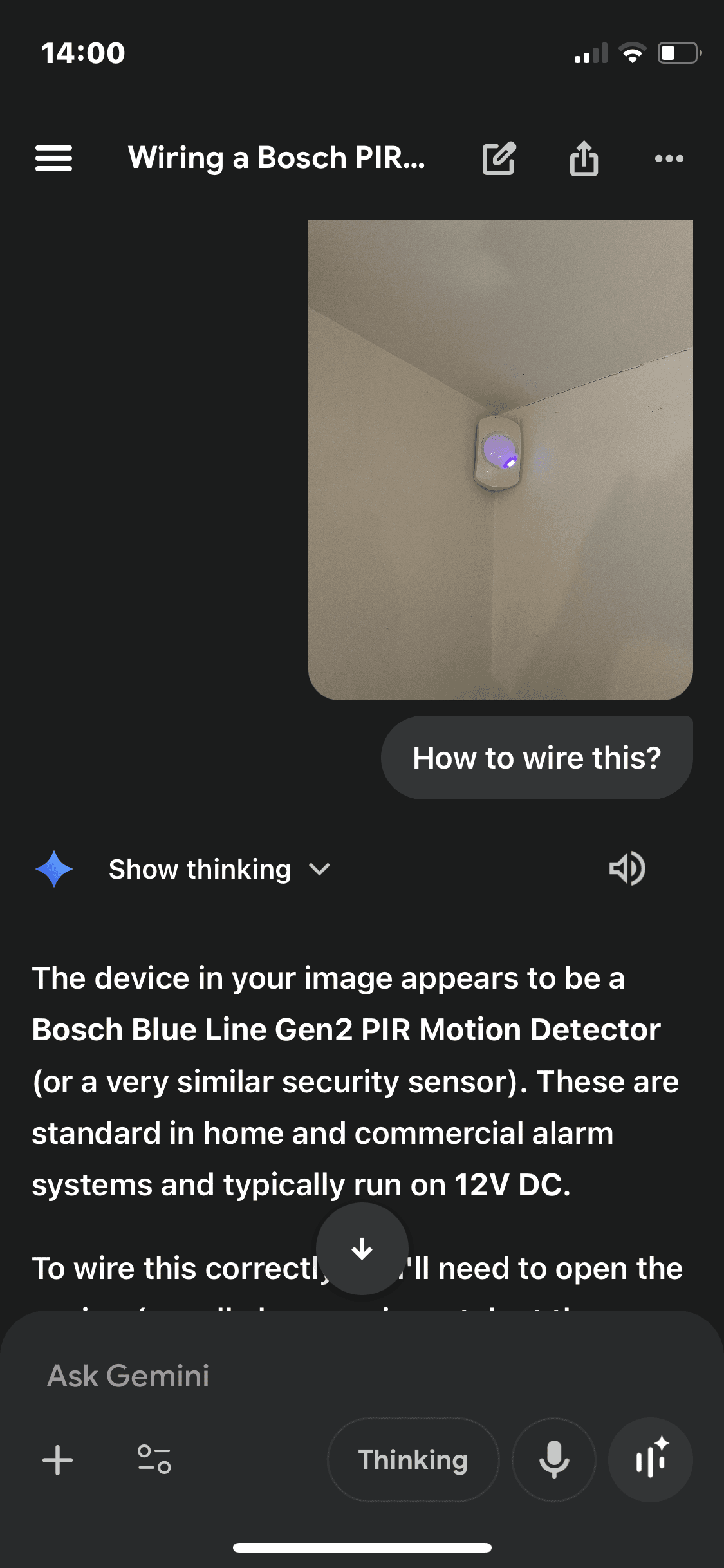
b) open the alarm panel box, in cramped conditions (see the photo example below of a real life scenario - in my cellar!)
c) test the system battery amongst a sea of wires
d) then check the sensors in the property, which requires mounting a ladder, and reaching up to unscrew the sensor cover, change the device the battery, and then replace sensor cover etc. etc.

The future of Trades
So, where does this leave the future of Tradespeople?
At this point, I should introduce my Dad - and his work-based obsessions over engineer efficiency. For the last 7 years I've been helping run my family's security company AMCO Security - installing / servicing intruder alarm systems.
My father has two main pet peeves which he believes are the secret to unlocking untold profitability: 1) Efficiency of engineers on the job (i.e. their ability to know what they're doing) 2) wasted time driving between jobs (i.e. dead time).
The basic economics of AMCO is that two thirds of revenue comes from engineer time. The more time engineers are doing work for clients, the more money made. Current weekly engineer productivity analysis indicates utility between 45 to 70%.
Imagine a time where that utility was closer to 100%. This is where Musk's and Super Engineer's world views converge.
AI augmentation not Robo-replacement
Given the magnitude of technical challenge ahead, a realistic prediction is that the Robo Engineer won't be a thing for at least 25 years - twice the time it took to produce self-driving cars.
The future vision of Trades is most likely one where simple / repetitive tasks are automated (e.g. driving), and complex real-world tasks are still carried out by human AI-augmented Tradespeople (i.e. Tradespeople assisted by AI via things like AI wearables - like Super Engineer & Super Spex).

A realistic near-future picture
To break-down the everyday activities of a Tradesperson, the near-future vision will look something like this:
Work planning / Briefing: jobs will be planned by an autonomous planner - estimating the most efficient routes and matching relevant workforce skillsets to specific job scenarios.
Transportation: this work plan will then be fed to a self-driving van, which will deliver the Tradesperson to their jobs - messaging the customer re: ETAs and unexpected delays, and detouring to Distributor partners to pick up parts / equipment (if necessary).
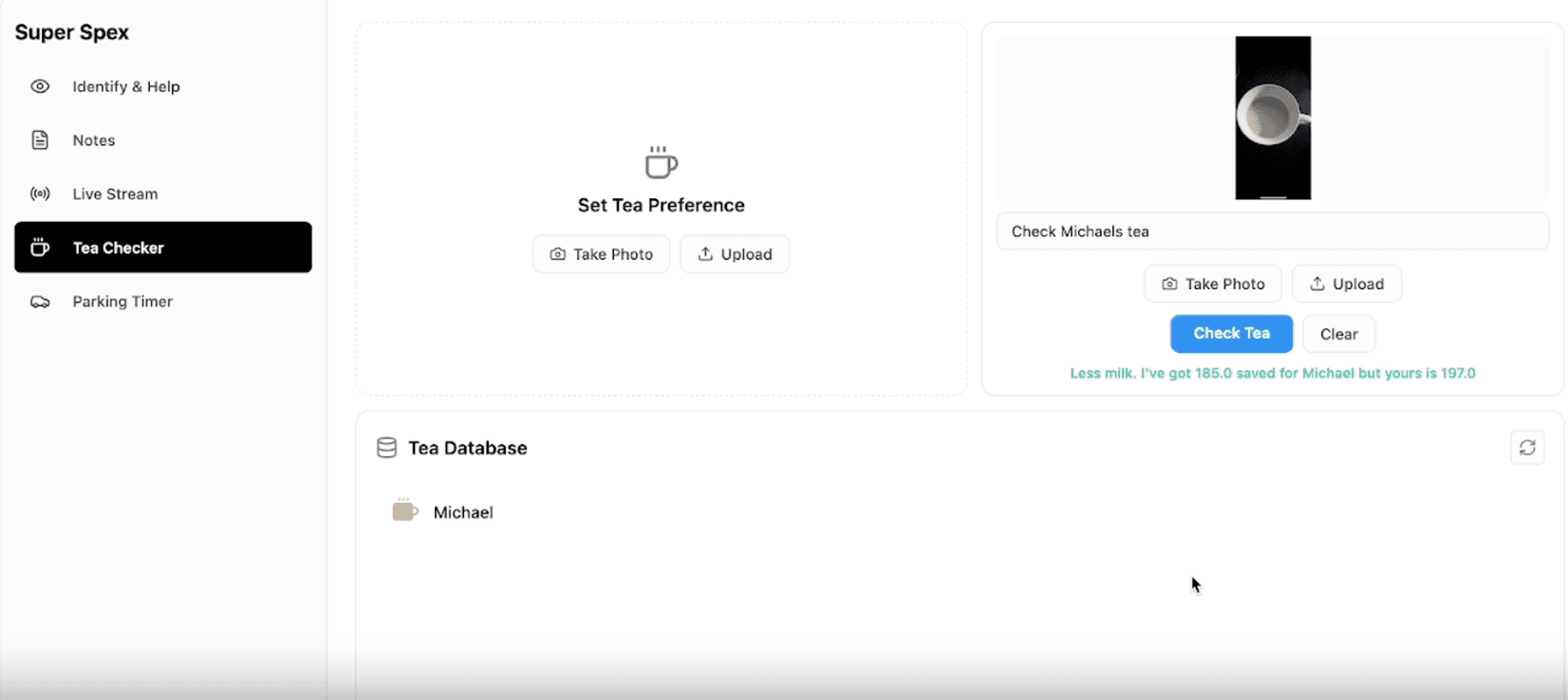
Site visit / manual work: when the Tradesperson reaches site, they'll pop on their Super Spex AI Glasses, and carry out the physical onsite work. The AI will guide the Tradesperson where necessary - acting as their personal assistant.
Reporting & communication: via AI Glasses technology (image & audio to text transcription), all work can be easily recorded and reported, and automatically saved / sent to HQ.
Trouble-shooting: any technical issue can be answered quickly via Super Engineer's AI - providing immediate specialist technical assistance.
Efficiency gains
Imagine if it was possible to increase engineer efficiency by say 15% (not a crazy increase) - due to AI augmentation speeding up time on site. This efficiency would drop straight through to utility increases (i.e. amount of engineer time spent on paid jobs) of say 10%.
At an average estimated cost of £20 an hour, and charge rate of £50 an hour, a 10% increase in utility of this resource is worth c.£7,000 extra revenue per year per engineer.
£100 billion impact
Consider then the sheer size of the service engineer market, which taking into account trades like electricians, fire / security, HVAC, Facility technicians is 600,000 in the UK, and 3 million in the US alone (estimated at 50 million globally).
Realistic estimates of the market revenue impacts of AI (based on a 10% utility increase, 50% adoption & 60% realisation rate) indicate an additional £1.2 billion revenue in the UK, £5.9 billion in the US - and a global impact of £100 billion.
Compliance and safety
Beyond economic gains, the use of AI in Trades has additional broader impacts linked to compliance and safety. In the UK, all industries require works to be implemented according to British Standards. The practical difficulty with this is the relative complexity of these standards, and the ability of the engineer to remember them - as the standards documents may run across 100's of pages.
Using AI like Super Engineer, British Standards can be directly injected into an engineer's workflows - in a simple / practical way, ensuring the Tradesperson works to the letter of the law.
The future is human
The future of the Tradesperson is clearly a very human-based future, which is hugely positive for the thriving community of Trades.
If you're an electrician, HVAC, fire/security technician, facility manager, then your jobs are safe for another 25+ years.
And excitingly, the timeline for this AI-enhanced vision of Trades is closer than you think:
AI Technical assistants are now available via Super Engineer
AI Glasses and wearables will be live in the next 12 months via Super Spex
Autonomous vans are likely to be available within a 2 to 10 year timeframe (depending on your location) and changes in legislation.
The future for Trades is one of the few areas of employment that will truly thrive in an AI world. For Trades, the future will be a world of AI-enhancements rather than robot domination.